Data encoding
Introduction and notation
To use a quantum algorithm, classical data must somehow be brought into a quantum circuit. This is usually referred to as data encoding, but is also called data loading. Recall from previous lessons the notion of a feature mapping, a mapping of data features from one space to another. Just transferring classical data to a quantum computer is a sort of mapping, and could be called a feature mapping. In practice, the built-in feature mappings in Qiskit (like z_feature_map and zz_feature_map) will typically include rotation layers and entangling layers that extend the state to many dimensions in the Hilbert space. This encoding process is a critical part of quantum machine learning algorithms and directly affects their computational capabilities.
Some of the encoding techniques below can be efficiently classically simulated; this is particularly easy to see in encoding methods that yield product states (that is, they do not entangle qubits). And remember that quantum utility is most likely to lie where the quantum-like complexity of the dataset is well-matched by the encoding method. So it is very likely that you will end up writing your own encoding circuits. Here, we show a wide variety of possible encoding strategies simply so that you can compare and contrast them, and see what is possible. There are some very general statements that can be made about the usefulness of encoding techniques. For example, efficient_su2 (see below) with a full entangling scheme is much more likely to capture quantum features of data than methods that yield product states (like z_feature_map). But this does not mean efficient_su2 is sufficient, or sufficiently well-matched to your dataset, to yield a quantum speed-up. That requires careful consideration of the structure of the data being modeled or classified. There is also a balancing act with circuit depth, since many feature maps which fully entangle the qubits in a circuit yield very deep circuits, too deep to get usable results on today's quantum computers.
Notation
A dataset is a set of data vectors: , where each vector is dimensional, that is, . This could be extended to complex data features. In this lesson, we may occasionally use these notations for the full set and its specific elements like . But we will mostly refer to the loading of a single vector from our dataset at a time, and will often simply refer to a single vector of features as .
Additionally, it is common to use the symbol to refer to the feature mapping of data vector . In quantum computing specifically, it is common to refer to mappings in quantum computing using a notation that reinforces the unitary nature of these operations. One could correctly use the same symbol for both; both are feature mappings. Throughout this course, we tend to use:
- when discussing feature mappings in machine learning, generally, and
- when discussing circuit implementations of feature mappings.
Normalization and information loss
In classical machine learning, training data features are often "normalized" or rescaled which often improves model performance. One common way of doing this is by using min-max normalization or standardization. In min-max normalization, feature columns of the data matrix (say, feature ) are normalized:
where min and max refer to the minimum and maximum of feature over the data vectors in the dataset . All the feature values then fall in the unit interval: for all , .
Normalization is also a fundamental concept in quantum mechanics and quantum computing, but it is slightly different from min-max normalization. Normalization in quantum mechanics requires that the length (in the context of quantum computing, the 2-norm) of a state vector is equal to unity: , ensuring that measurement probabilities sum to 1. The state is normalized by dividing by the 2-norm; that is, by rescaling
In quantum computing and quantum mechanics, this is not a normalization imposed by people on the data, but a fundamental property of quantum states. Depending on your encoding scheme, this constraint may affect how your data are rescaled. For example, in amplitude encoding (see below), the data vector is normalized as is required by quantum mechanics, and this affects the scaling of the data being encoded. In phase encoding, feature values are recommended to be rescaled as so that there is no information loss due to the modulo- effect of encoding to a qubit phase angle[1,2].
Methods of encoding
In the next few sections, we will refer to a small example classical dataset consisting of data vectors, each with features:
In the notation introduced above, we might say the feature of the data vector in our set is for example.
Basis encoding
Basis encoding encodes a classical -bit string into a computational basis state of a -qubit system. Take for example This can be represented as a -bit string as , and by a -qubit system as the quantum state . More generally, for a -bit string: , the corresponding -qubit state is with for . Note that this is just for a single feature.
Basis encoding in quantum computing represents each classical bit as a separate qubit, mapping the binary representation of data directly onto quantum states in the computational basis. When multiple features need to be encoded, each feature is first converted to its binary form and then assigned to a distinct group of qubits — one group per feature — where each qubit reflects a bit in the binary representation of that feature.
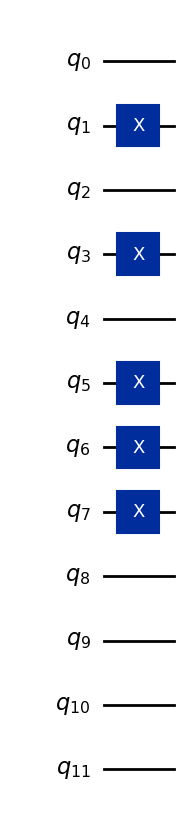
As an example, let us encode the vector (5, 7, 0).
Suppose all features are stored in four bits (more than we need, but enough to represent any integer that is single-digit in base 10):
5 → binary 0101
7 → binary 0111
0 → binary 0000
These bit strings are assigned to three sets of four qubits, so the overall 12-qubit basis state is:
Here, the first four qubits represent the first feature, the next four qubits the second feature, and the last four qubits the third feature. The code below converts the data vector (5,7,0) to a quantum state, and is generalized to do so for other single-digit features.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Check your understanding
Write code to encode the first vector in our example data set :
using basis encoding.
Answer
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Amplitude encoding
Amplitude encoding encodes data into the amplitudes of a quantum state. It represents a normalized classical -dimensional data vector, , as the amplitudes of a -qubit quantum state, :
where is the same dimension of the data vectors as before, is the element of and is the computational basis state. Here, is a normalization constant to be determined from the data being encoded. This is the normalization condition imposed by quantum mechanics:
In general, this is a different condition than the min/max normalization used for each feature across all data vectors. Precisely how this is navigated will depend on your problem. But there is no way around the quantum mechanical normalization condition above.
In amplitude encoding, each feature in a data vector is stored as an amplitude of a different quantum state. As a system of qubits provides amplitudes, amplitude encoding of features requires qubits.
As an example, let's encode the first vector in our example dataset , using amplitude encoding. Normalizing the resulting vector, we get:
and the resulting 2-qubit quantum state would be:
In the example above, the number of features in the vector , is not a power of 2. When is not a power of 2, we simply choose a value for the number of qubits such that and pad the amplitude vector with uninformative constants (here, a zero).
Like in basis encoding, once we calculate what state will encode our dataset, in Qiskit we can use the initialize function to prepare it:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

An advantage of amplitude encoding is the aforementioned requirement of only qubits to encode. However, subsequent algorithms must operate on the amplitudes of a quantum state, and methods to prepare and measure the quantum states tend not to be efficient.
Check your understanding
Write down the normalized state for encoding the following vector (made of two vectors from our example dataset):
using amplitude encoding.
Answer
To encode 6 numbers, we will need to have at least 6 available states on whose amplitudes we can encode. This will require 3 qubits. Using an unknown normalization factor , we can write this as:
Note that
So finally,
For the same data vector write code to create a circuit that loads these data features using amplitude encoding.
Answer
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

You may need to deal with very large data vectors. Consider the vector
Write code to automate the normalization, and generate a quantum circuit for amplitude encoding.
Answer
There are many possible answers. Here is code that prints a few steps along the way:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Do you see advantages to amplitude encoding over basis encoding? If so, explain.
Answer
There may be several answers. One answer is that, given the fixed ordering of the basis states, this amplitude encoding preserves the order of the numbers encoded. It will often also be encoded more densely.
A benefit of amplitude encoding is that only qubits are required for an -dimensional (-feature) data vector . However, amplitude encoding is generally an inefficient procedure that requires arbitrary state preparation, which is exponential in the number of CNOT gates. Stated differently, the state preparation has a polynomial runtime complexity of in the number of dimensions, where , and is the number of qubits. Amplitude encoding “provides an exponential saving in space at the cost of an exponential increase in time”[3]; however, runtime increases to are achievable in certain cases[4]. For an end-to-end quantum speedup, the data loading runtime complexity needs to be considered.
Angle encoding
Angle encoding is of interest in many QML models using Pauli feature maps such as quantum support vector machines (QSVMs) and variational quantum circuits (VQCs), among others. Angle encoding is closely related to phase encoding and dense angle encoding which are presented below. Here we will use "angle encoding" to refer to a rotation in , that is, a rotation away from the axis accomplished for example by an gate or an gate[1,3]. Really, one can encode data in any rotation or combination of rotations. But is common in the literature, so we emphasize it here.
When applied to a single qubit, angle encoding imparts a Y-axis rotation proportional to the data value. Consider the encoding of a single ()feature from the data vector in a dataset, :
Alternatively, angle encoding can be performed using gates, although the encoded state would have a complex relative phase compared to .
Angle encoding is different from the previous two methods discussed in several ways. In angle encoding:
- Each feature value is mapped to a corresponding qubit, , leaving the qubits in a product state.
- One numerical value is encoded at a time, rather than a whole set of features from a data point.
- qubits are required for data features, where . Often equality holds, here. We'll see how is possible in the next few sections.
- The resulting circuit is a constant depth (typically the depth is 1 prior to transpilation).
The constant depth quantum circuit makes it particularly amenable to current quantum hardware. One additional feature of encoding our data using (and specifically, our choice to use Y-axis angle encoding) is that it creates real-valued quantum states that can be useful for certain applications. For Y-axis rotation, data is mapped with a Y-axis rotation gate by a real-valued angle (Qiskit RYGate). As with phase encoding (see below), we recommend that you rescale data so that , preventing information loss and other unwanted effects.
The following Qiskit code rotates a single qubit from an initial state to encode a data value .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
We will define a function to visualize the action on the state vector. The details of the function definition are not important, but the ability to visualize the state vectors and their changes is important.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

That was just a single feature of a single data vector. When encoding features into the rotation angles of qubits, say for the data vector the encoded product state will look like this:
We note that this is equivalent to
Check your understanding
Encode the data vector using angle encoding, as described above.
Answer
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Using angle encoding as described above, how many qubits are required to encode 5 features?
Answer
5
Phase encoding
Phase encoding is very similar to the angle encoding described above. The phase angle of a qubit is a real-valued angle about the -axis from the +-axis. Data are mapped with a phase rotation, , where (see Qiskit PhaseGate for more information). It is recommended to rescale data so that . This prevents information loss and other potentially unwanted effects[1,2].
A qubit is often initialized in the state , which is an eigenstate of the phase rotation operator, meaning that the qubit state first needs to be rotated for phase encoding to be implemented. It therefore makes sense to initialize the state with a Hadamard gate: . Phase encoding on a single qubit means imparting a relative phase proportional to the data value:
The phase encoding procedure maps each feature value to the phase of a corresponding qubit, . In total, phase encoding has a circuit depth of 2, including the Hadamard layer, which makes it an efficient encoding scheme. The phase-encoded multi-qubit state ( qubits for features) is a product state:
The following Qiskit code first prepares the initial state of a single qubit by rotating it with a Hadamard gate, then rotates it again using a phase gate to encode a data feature .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

We can visualize the rotation in using the plot_Nstates function we defined.
plot_Nstates(states, axis=None, plot_trace_points=True)

The Bloch sphere plot shows the Z-axis rotation where . The light green arrow shows the final state.
Phase encoding is used in many quantum feature maps, particularly and feature maps, and general Pauli feature maps, among others.
Check your understanding
How many qubits are required in order to use phase encoding as described above to store 8 features?
Answer
8
Write code to the vector using phase encoding.
Answer
There may be many answers. Here is one example:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Dense angle encoding
Dense angle encoding (DAE) is a combination of angle encoding and phase encoding. DAE allows two feature values to be encoded in a single qubit: one angle with a Y-axis rotation angle, and the other with a -axis rotation angle: . It encodes two features as follows:
Encoding two data features to one qubit results in a reduction in the number of qubits required for the encoding. Extending this to more features, the data vector can be encoded as:
DAE can be generalized to arbitrary functions of the two features instead of the sinusoidal functions used here. This is called general qubit encoding[7].
As an example of DAE, the code below encodes and visualizes the encoding of the features and .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Check your understanding
Given the treatment above, how many qubits are needed to encode 6 features using dense encoding?
Answer
3
Write code to load the vector using dense angle encoding.
Answer
Note that we have padded the list with a "0" to avoid the problem of there being a single unused parameter in our encoding scheme.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Encoding with built-in feature maps
Encoding at arbitrary points
Angle encoding, phase encoding, and dense encoding prepared product states with a feature encoded on each qubit (or two features per qubit). This is different from basis encoding and amplitude encoding, in that those methods make use of entangled states. There is not a 1:1 correspondence between data feature and qubit. In amplitude encoding, for example, you might have one feature as the amplitude of the state and another feature as the amplitude for . Generally, methods that encode in product states yield shallower circuits and can store 1 or 2 features on each qubit. Methods that use entanglement and associate a feature with a state rather than a qubit result in deeper circuits, and can store more features per qubit on average.
But encoding need not be entirely in product states or entirely in entangled states as in amplitude encoding. Indeed, many encoding schemes built into Qiskit allow encoding both before and after an entanglement layer, as opposed to just at the beginning. This is known as "data reuploading". For related work, see references [5] and [6].
In this section, we will use and visualize a few of the built-in encoding schemes. All the methods in this section encode features as rotations on parameterized gates on qubits, where . Note that maximizing data loading for a given number of qubits is not the only consideration. In many cases, circuit depth may be an even more important consideration than qubit count.
Efficient SU2
A common and useful example of encoding with entanglement is Qiskit's efficient_su2 circuit. Impressively, this circuit can, for example, encode 8 features on only 2 qubits. Let's see this, and then try to understand how it is possible.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

As we write our state, we will use the Qiskit convention that least-significant qubits are ordered to the far right, as in or These states can become very complicated very quickly, and this rare example may help explain why such states are seldom written out explicitly.
Our system starts in the state Up to the first barrier (a point we label ), our states are:
That's just dense encoding, which we've seen before. Now after the CNOT gate, at the second barrier (), our state is
We now apply the last set of single-qubit rotations and collect like states to obtain:
This is likely too complicated to parse. Instead, just step back and think about how many parameters we loaded onto the state: eight. But we have with just four computational basis states. At first glance, it may appear that we have loaded more parameters than makes sense, since the final state can be written as . Note, however, that each prefactor is complex! Written like this:
One can see that we do, indeed, have eight parameters on the state on which to encode our eight features.
By increasing the number of qubits and increasing the number of repetitions of entangling and rotation layers, one can encode much more data. Writing out the wave functions quickly becomes intractable. But we can still see the encoding in action.
Here we encode the data vector with 12 features, on a 3-qubit efficient_su2 circuit, using each of the parameterized gates to encode a different feature.
In this data vector, the features are shown in a particular order. In isolation, it doesn't matter if they are encoded in this order or in the reverse. What is important is keeping track of it and being consistent. Note in the circuit diagram that efficient_su2 assumes a certain ordering of encoding, specifically filling the first layer of parameterized gates from qubit 0 to qubit 2, and then moving to the next layer. This is neither consistent nor inconsistent with little-endian notation, since here the data features cannot be ordered by qubit a priori, before an encoding circuit has been specified.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Instead of increasing the number of qubits, you might choose to increase the number of repetitions of entangling and rotation layers. But there are limits to how many repetitions are useful. As previously stated, there is a tradeoff: circuits with more qubits or more repetitions of entangling and rotation layers may store more parameters, but do so with greater circuit depth. We will return to the depths of some built-in feature maps, below. The next few encoding methods that are built into Qiskit have "feature map" as part of their names. Let us reiterate that encoding data into a quantum circuit is a feature mapping, in the sense that it takes data into a new space: the Hilbert space of the qubits involved. The relationship between the dimensionality of the original feature space and that of the Hilbert space will depend on the circuit you use for encoding.
feature map
The feature map (ZFM) can be interpreted as a natural extension of phase encoding. The ZFM consists of alternating layers of single-qubit gates: Hadamard gate layers and phase gate layers. Let the data vector have features. The quantum circuit that performs the feature mapping is represented as a unitary operator that acts on the initial state:
where is the -qubit ground state. This notation is used for consistency with reference [4] Havlicek et al. The data features are mapped one-to-one with corresponding qubits. For example, if you have 8 features in a data vector, then you would use 8 qubits. The ZFM circuit is composed of repetitions of a subcircuit comprised of Hadamard gate layers and phase gate layers. A Hadamard layer is made up of a Hadamard gate acting on every qubit in an -qubit register, , within the same stage of the algorithm. This description also applies to a phase gate layer in which the qubit is acted on by . Each gate has one feature as an argument, but the phase gate layer ( is a function of the data vector. The full ZFM circuit unitary with a single repetition is:
Then repetitions of this unitary would be
The data features, , are mapped to the phase gates in the same way in all repetitions. The ZFM feature map state is a product state and is efficient for classical simulation[4].
To start with a small example, a two-qubit ZFM circuit is coded using Qiskit and drawn to display the simple circuit structure. In the example, a single repetition, , is implemented with the data vector . Note that this is written in the standard order of a vector in Python, meaning the element is We are free to encode this feature onto our qubit, or onto our Again, there cannot always be a single 1:1 mapping from feature order to qubit order, since different feature maps encode different numbers of features to each qubit. Again what is important is that we are aware of where each feature is being encoded. When providing a parameter list to the feature map, it will encode feature 0 from the list to the least-significant qubit with a parameterized gate, as in qubit 0. So we will follow that convention when doing this by hand. We will encode on the qubit, and on the qubit.
The ZFM circuit unitary operator acts on the initial state in the following way:
The formula has been rearranged around the tensor product to emphasize the operations on each qubit. The following Qiskit code uses Hadamard and phase gates explicitly to show the structure of the ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

We now encode the same data vector to a ZFM circuit with three repetitions, , using the Qiskit z_feature_map class, which altogether gives us the quantum feature map . By default in the z_feature_map class, parameters are multiplied by 2 before mapping to the phase gate . To reproduce the same encodings as above, we divide by 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Clearly this is a different mapping from the one done by hand above, but note the consistency in parameter ordering: was again encoded on the qubit.
You may use ZFM via Qiskit's ZFM class; you can also use this structure as inspiration to construct your own feature mapping.
feature map
The feature map (ZZFM) extends the ZFM with the inclusion of two-qubit entangling gates, specifically the -rotation gate . The ZZFM is conjectured to be generally expensive to compute on a classical computer, unlike the ZFM.
implements a -interaction and is maximally entangling for . can be decomposed into a series of gates on two qubits, as shown in the following Qiskit code using the RZZ gate and the QuantumCircuit class method decompose. We encode a single feature of the data vector :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

As is often the case, we see this represented as a single gate-like unit, until we use .decompose() to see all constituent gates.
qc.decompose().draw("mpl", scale=1)

Data is mapped with a phase rotation on the second qubit. The gate entangles the two qubits on which it operates by a degree of entanglement determined by the encoded feature value.
The full ZZFM circuit consists of a Hadamard gate and phase gate, as in the ZFM, followed by the entanglement described above. A single repetition of the ZZFM circuit is:
where contains ZZ-gate layer structured by an entanglement scheme. Several entanglement schemes are shown in code blocks below. The structure of also includes a function that combines the data features from qubits being entangled in the following way. Let us say that the gate is to be applied to qubits and . In the phase layer, these qubits have phase gates that encode and on them, respectively. The argument of the will not simply be one of these features or the other, but a function often denoted by (not to be confused with the azimuthal angle):
We will see this in several examples below. The extension to multiple repetitions is the same as in the z_feature_map case:
As the operators have increased in complexity, let us first encode a data vector with a two-qubit ZZFM and one repetition using the following code:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

By default in Qiskit, the features are mapped together to by this mapping function . Qiskit allows the user to customize the function (or where is the set of qubit pairs coupled through gates) as a preprocessing step.
Moving to a four-dimensional data vector and mapping to a four-qubit ZZFM with one repetition, we can start to see the mapping for various qubit pairs. We can also see the meaning of "linear" entanglement:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

In the linear entanglement scheme, nearest-neighbor (numbered) pairs of qubits in this circuit are entangled. There are other built-in entanglement schemes in Qiskit, including circular and full.
Pauli feature map
The Pauli feature map (PFM) is the generalization of the ZFM and ZZFM to use arbitrary Pauli gates. The Pauli feature map takes a very similar form to the previous two feature maps. For repetitions of the encoding of the features of vector
For PFM, is generalized to a Pauli expansion unitary operator. Here we present a more generalized form of the feature maps considered so far:
where is a Pauli operator, . Here is the set of all qubit connectivities as determined by the feature map, including the set of qubits acted on by single-qubit gates. That is, for a feature map in which qubit 0 was acted upon by a phase gate, and qubits 2 and 3 were acted upon by an gate, the set would include . runs through all elements of that set. In previous feature maps, the function was involved either exclusively with single-qubit gates or exclusively with two-qubit gates. Here, we define it in general:
For documentation, see the Qiskit Pauli feature map class documentation). In the ZZFM, the operator is restricted to .
One way to understand the above unitary is through analogy with the propagator in a physical system. The unitary above is a unitary evolution operator, , for a Hamiltonian, , similar to the Ising model, where the time parameter, , is replaced with data values to drive the evolution. The expansion of this unitary operator gives the PFM circuit. The entangling connectivities in can be interpreted as Ising couplings in a spin lattice.
Let us consider an example of Pauli and operators representing those Ising-type interactions. Qiskit provides a pauli_feature_map class for instantiating a PFM with a choice of single- and -qubit gates, which in this example will be passed as Pauli strings ‘Y’ and ‘XX’. Typically, is 1 or 2 for single- and two-qubit interactions, respectively. The entanglement scheme is “linear,” meaning that only nearest-neighbor qubits in the quantum circuit are coupled. Note that this does not correspond to nearest-neighbor qubits on the quantum computer itself, as this quantum circuit is an abstraction layer.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit provides a parameter, , in Pauli feature maps to control the scaling of Pauli rotations.
The default value of is . By optimizing its value in the interval, for example, one can better align a quantum kernel to the data.
Gallery of Pauli feature maps
Here we visualize various Pauli feature maps for two-qubit circuits to get a better picture of the range of possibilities.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
The above can, of course, be extended to include other permutations and repetitions of Pauli matrices. Learners are encouraged to experiment with those options.
Review of built-in feature maps
You have seen several schemes for encoding data into a quantum circuit:
- Basis encoding
- Amplitude encoding
- Angle encoding
- Phase encoding
- Dense encoding
You have seen how to construct your own feature maps using these encoding schemes, and you have seen four built-in feature maps which take advantage of angle and phase encoding:
- Efficient SU2
- Z feature map
- ZZ feature map
- Pauli feature map
These built-in feature maps differed from each other in several ways:
- The depth for a given number of encoded features
- The number of qubits required for a given number of features
- The degree of entanglement (obviously related to the other differences)
The code below applies these four built-in feature maps to the encoding of a feature set, and plots the two-qubit depth of the resulting circuit. Since two-qubit error rates are much higher than single-qubit gate error rates, one might reasonably be most interested in the depth of two-qubit gates. In the code below, we obtain counts of all gates in a circuit by first decomposing the circuit and then using count_ops(), as shown below. Here the two-qubit gates we are interested in are 'cx' gates:
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Generally Pauli and ZZ feature maps will result in greater circuit depth and higher numbers of 2-qubit gates than efficient_su2 and Z feature maps.
Because the feature maps built into Qiskit are widely applicable, we will often not need to design our own, especially in the learning phase. However, experts in quantum machine learning will likely return to the subject of designing their own feature mapping, as they tackle two complicated challenges:
-
Modern hardware: the presence of noise and the large overhead of error-correcting code mean that present-day applications will need to consider things like hardware efficiency and minimizing two-qubit gate depth.
-
Mappings that fit the problem at hand: It is one thing to say that the
zz_feature_map, for example, is difficult to simulate classically, and therefore interesting. It is quite another thing for thezz_feature_mapto be ideally suited to your machine learning task or data set. The performance of different parameterized quantum circuits on different types of data is an active area of investigation.
We close with a note on hardware efficiency.
Hardware-efficient feature mapping
A hardware-efficient feature mapping is one that takes into account constraints of real quantum computers, in the interest of reducing noise and errors in the computation. When running quantum circuits on near-term quantum computers, there are many strategies to mitigate noise inherent to the hardware. One main strategy for hardware efficiency is the minimization of the depth of the quantum circuit so that noise and decoherence have less time to corrupt the computation. The depth of a quantum circuit is the number of time-aligned gate steps required to complete the entire computation (after circuit optimization)[5]. Recall that the depth of the abstract, logical circuit may be much lower than the depth once the circuit is transpiled for a real quantum computer.
Transpilation is the process of converting the quantum circuit from a high-level abstraction to one that is ready to run on a real quantum computer, taking into account constraints of the hardware. A quantum computer has a native set of single- and two-qubit gates. This means all gates in Qiskit code have to be transpiled into the set of native hardware gates. For example, in ibm_torino, a QPU sporting a Heron r1 processor and completed in 2023, the native or basis gates are {CZ, ID, RZ, SX, X}. These are the two-qubit controlled-Z gate, and single-qubit gates called identity, -rotation, square root of NOT, and NOT, respectively, providing a universal set. When implementing multi-qubit gates as an equivalent subcircuit, physical two-qubit gates are required, along with other single-qubit gates available in hardware. In addition, to perform a two-qubit gate on a pair of qubits that are not physically coupled, SWAP gates are added to move qubit states between qubits to enable coupling, which leads to an unavoidable extension of the circuit. Using the optimization argument that can be set from 0 up to a highest level of 3. For greater control and customizability, the transpiler pipeline can be managed with the Qiskit Pass Manager. Refer to the Qiskit Transpiler documentation for more information on transpilation.
In Havlicek et al. 2019 [2], one way the authors achieve hardware efficiency is by using the feature map because it is a second-order expansion (see the “ feature map” section above). An -order expansion has -qubit gates. IBM® quantum computers do not have native -qubit gates, where , so to implement them would require decomposition into two-qubit CNOT gates available in hardware. A second way the authors minimize depth is by choosing a coupling topology that maps directly to the architecture couplings. A further optimization they undertake is targeting a higher-performing, suitably connected hardware subcircuit. Additional things to consider are minimizing the number of feature map repetitions and choosing a customized low-depth or “linear” entangling scheme instead of the “full” scheme that entangles all qubits.

The above graphic shows a network of nodes and edges that represent physical qubits and hardware couplings, respectively. The coupling map and performance of ibm_torino is shown with all possible two-qubit CZ coupling gates. Qubits are color-coded on a scale based on the T1 relaxation time in microseconds (μs), where longer T1 times are better and in a lighter shade. The coupling edges are color-coded by CZ error, where darker shades are better. Information on the hardware specification can be accessed in the hardware backend configuration schema IBMQBackend.configuration().
References
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., “Supervised Learning with Quantum Enhanced Feature Spaces.” Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. “Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions.” arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()